同時度数分布
とりあえず東証平均の収益率と同時期の新日鉄の収益率を入力する。
(ここではエクセルに入力してあったデータをコピペした)
(ここではエクセルに入力してあったデータをコピペした)
tosho<-scan() 1: 1.9 0.0 -2.1 2.9 0.0 1.1 -0.3 1.6 2.7 1.5 -0.6 0.3 13: 3.3 -0.4 5.3 6.0 -0.1 4.7 1.0 -0.4 -6.1 0.4 0.4 2.9 25: 2.2 -4.9 -3.0 2.3 0.1 -1.3 -1.5 -0.1 -0.5 3.6 6.6
tosho<-ts(tosho,frequency=12,start=1980)
tosho
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1980 1.9 0.0 -2.1 2.9 0.0 1.1 -0.3 1.6 2.7 1.5 -0.6 0.3
1981 3.3 -0.4 5.3 6.0 -0.1 4.7 1.0 -0.4 -6.1 0.4 0.4 2.9
1982 2.2 -4.9 -3.0 2.3 0.1 -1.3 -1.5 -0.1 -0.5 3.6 6.6 2.7
1983 -0.9 0.7 5.0 2.4 0.9 3.1 1.5 2.0 2.4 -0.8 0.6 6.5
1984 6.1 -0.2 12.7 -1.0 -9.9 2.6 -4.1 7.0 1.4 4.6 2.0 4.3
shinnittetu<-ts(shinnittetu,frequency=12,start=1980)
shinnittetu
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
1980 9.2 2.3 -6.5 9.0 5.3 -4.3 -3.7 7.0 7.6 1.4 -3.4 0.7
1981 2.8 -1.4 17.6 17.8 5.5 -1.9 1.9 9.0 -10.3 -10.3 -7.7 6.5
1982 -0.6 -11.8 3.5 1.9 -5.5 -9.1 -5.7 2.3 -4.9 -0.8 8.0 6.7
1983 -2.8 9.3 11.4 3.0 -7.5 2.5 -0.6 1.8 5.1 -2.3 -6.0 10.6
1984 0.0 -5.7 10.6 -0.6 -11.2 -3.8 -5.2 6.2 -4.2 2.1 0.6 4.7
東証平均と新日鉄のデータについて、データの範囲と大体の分布をみるために、5 数要約 fivenum() : 最小値・下側ヒンジ・中央値・上側ヒンジ・最大値を見る。
fivenum(tosho) [1] -9.90 -0.35 1.25 2.90 12.70 fivenum(shinnittetu) [1] -11.80 -4.25 1.05 5.85 17.80
さて、この2つのデータから同時度数分布を作ろう。
まず連続変数をカテゴリー変数に変換するために使用するのは cut 関数である。
区切り(2刻み)を変数breaksにいれて
まず連続変数をカテゴリー変数に変換するために使用するのは cut 関数である。
区切り(2刻み)を変数breaksにいれて
breaks<-seq(-10,14,by=2) breaks2<-seq(-12,18,by=2)
cut()を使う。「○○以上□□未満」の場合は right = FALSE にする必要がある。
c_tosho<-cut(tosho,breaks,right=F) c_shinnittetu<-cut(sinnittetu,breaks2,right=F)
カテゴリー化できたら、それらをつかってクロス表をつくる。
table(c_tosho,c_shinnittetu)
これすなわち同時度数分布となっている。
c_shinnittetu
c_tosho [-12,-10) [-10,-8) [-8,-6) [-6,-4) [-4,-2) [-2,0) [0,2) [2,4)
[-10,-8) 1 0 0 0 0 0 0 0
[-8,-6) 1 0 0 0 0 0 0 0
[-6,-4) 1 0 0 1 0 0 0 0
[-4,-2) 0 0 1 0 0 0 0 1
[-2,0) 0 1 0 3 4 2 0 1
[0,2) 1 0 2 4 0 1 3 1
[2,4) 0 0 0 0 1 2 3 3
[4,6) 0 0 0 0 0 1 0 1
[6,8) 0 0 0 0 0 0 1 0
[8,10) 0 0 0 0 0 0 0 0
[10,12) 0 0 0 0 0 0 0 0
[12,14) 0 0 0 0 0 0 0 0
c_shinnittetu
c_tosho [4,6) [6,8) [8,10) [10,12) [12,14) [14,16) [16,18)
[-10,-8) 0 0 0 0 0 0 0
[-8,-6) 0 0 0 0 0 0 0
[-6,-4) 0 0 0 0 0 0 0
[-4,-2) 0 0 0 0 0 0 0
[-2,0) 1 0 1 0 0 0 0
[0,2) 1 1 2 0 0 0 0
[2,4) 1 3 1 0 0 0 0
[4,6) 1 0 0 1 0 0 1
[6,8) 0 1 1 1 0 0 1
[8,10) 0 0 0 0 0 0 0
[10,12) 0 0 0 0 0 0 0
[12,14) 0 0 0 1 0 0 0
これを3次元のグラフにしよう。
同時度数分布なので、同時度数グラフとか3次元ヒストグラムとか呼ばれる。
同時度数分布なので、同時度数グラフとか3次元ヒストグラムとか呼ばれる。
まず3次元データとして使いやすいようにデータを加工する。変数matにクロス集計を格納して、
mat<-table(c_tosho,c_shinnittetu)
これを次のようなデータ・フレーム形式にする。
s3d.dat <- data.frame(cols=as.vector(col(mat)),rows=as.vector(row(mat)),value=as.vector(mat))
何をやっているかは、結果を見た方が理解が早い。
s3d.dat
cols rows value
1 1 1 1
2 1 2 1
3 1 3 1
4 1 4 0
5 1 5 0
6 1 6 1
7 1 7 0
……(中略)……
176 15 8 1
177 15 9 1
178 15 10 0
179 15 11 0
180 15 12 0
つまりm行目のn列目の数値はいくつであるか、を並べているのである。
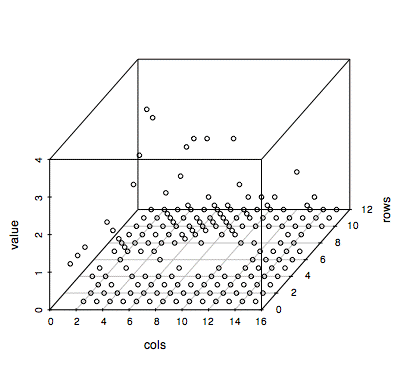
これをscatterplot3d()に渡してやると、まずは三次元にぶつぶつが浮かぶ。
scatterplot3d(s3d.dat)
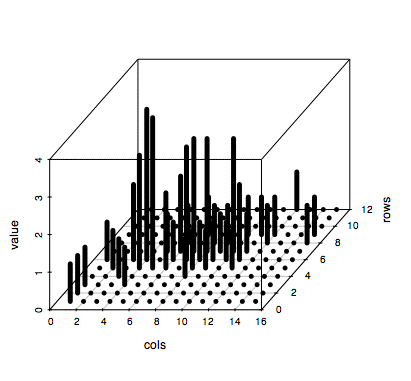
これを棒グラフっぽくするには、type="h"とし、太さを lwd=5で少し太らせ、 pch=" "で、棒の先端についたキャラクタを外す。
scatterplot3d(s3d.dat,type="h", lwd=5, pch=" ")
散布図
二つの量の関係を確かめるには、散布図が一番だ。
散布図は普通、
散布図は普通、
plot(x,y)
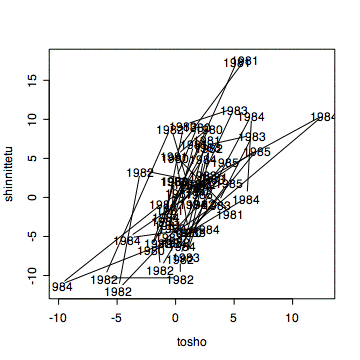
の形で描けるが、いま扱っているデータは、toshoもshinnitetuも時系列データで、そのまま
plot(tosho,shinnitetu)
では、時系列の順に結ばれる折れ線グラフとなる。
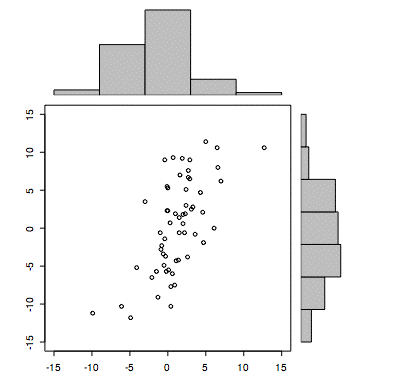
普通の散布図が欲しい場合には、as.vector()関数で、データをベクトル・データに変換してやればいい。
ここでは、少し工夫して、それぞれのヒストグラムをつけた散布図を書いてみる。
xhist <- hist(tosho, plot=FALSE) # 棒グラフ情報を記録 yhist <- hist(shinnittetu, plot=FALSE) # 棒グラフ情報を記録 top <- max(c(xhist$counts, yhist$counts)) xrange <- c(-15,15) yrange <- c(-15,15) # layout 関数で画面を横に 3:1、縦に1:3 の4画面に分割 # 副画面の番号を [1,1] -> 2, [1,2] -> 0, [2,1] -> 1, [2,2] -> 3 とする # 番号 0 の副画面には何も描かない(?) nf <- layout(matrix(c(2,0,1,3),2,2,byrow=TRUE), c(3,1), c(1,3), TRUE) par(mar=c(3,3,1,1)) #番号1の副画面の余白指定 plot(as.vector(tosho), as.vector(shinnittetu), xlim=xrange, ylim=yrange, xlab="", ylab="") # 番号1の副画面にプロット par(mar=c(0,3,1,1)) #番号2の副画面の余白指定 barplot(xhist$counts, axes=FALSE, ylim=c(0, top), space=0) # 番号2の副画面にプロット par(mar=c(3,0,1,1)) #番号3の副画面の余白指定 barplot(yhist$counts, axes=FALSE, xlim=c(0, top), space=0, horiz=TRUE) # 番号3の副画面にプロット
相関係数
n組のデータ(x1、y1)……(xn、yn)で与えられる、2変数の関係を表す指標を考えよう。
東証平均と新日鉄のデータをベクトル・データに変換しておく。
東証平均と新日鉄のデータをベクトル・データに変換しておく。
v.tosho<-as.vector(tosho) v.shinnittetu<-as.vector(shinnittetu)
データはそれぞれxの平均、yの平均のまわりに散らばっている。
平均まわりの散らばり具合を、平均からの偏差で考える。
xの偏差がプラス(マイナス)で、yの偏差がプラス(マイナス)なら、両者の関係もプラスだろうと考えるのが自然である。
同様に、xの偏差がマイナス(プラス)で、yの偏差がプラス(マイナス)なら、両者の関係もマイナスだろうと考えるのが自然である。
データそれぞれについて、偏差の積を考え、それらの平均を得ると、共分散という指数が得られる。すなわち
平均まわりの散らばり具合を、平均からの偏差で考える。
xの偏差がプラス(マイナス)で、yの偏差がプラス(マイナス)なら、両者の関係もプラスだろうと考えるのが自然である。
同様に、xの偏差がマイナス(プラス)で、yの偏差がプラス(マイナス)なら、両者の関係もマイナスだろうと考えるのが自然である。
データそれぞれについて、偏差の積を考え、それらの平均を得ると、共分散という指数が得られる。すなわち
1/length(v.tosho)*sum( ( (v.tosho-mean(v.tosho) )*( (v.shinnittetu-mean(v.shinnittetu) ) ) ) ) [1] 15.18402
しかし例のごとく、この量ははかる単位に依存する。依存しないようにするために、xの標準偏差とyの標準偏差で割っておこう。
以前つくった標準偏差を求める関数を思い出そう。関数名を()抜きでタイプしてエンター・キーを押すと、関数の「中身」が見れる。
sampleSD
function(x){sqrt(sampleVar(x))}
これをつかって、東証平均と新日鉄のデータそれぞれの標準偏差を求める。
sampleSD(v.tosho) [1] 3.390255 sampleSD(v.shinnittetu) [1] 6.738344
あとは、これらで共分散を割ってやる
15.18402/(3.390255*6.738344) [1] 0.6646626
この指標を相関係数という。相関係数を2系列のデータから求めるには、Rに用意されているcor()関数を使えばいい。
cor(v.tosho,v.shinnittetu) [1] 0.6646628
相関係数は−1〜+1の値をとる性質がある。0(ゼロ)ときは相関がないといい、+1のときは最も強いプラスの相関が、−1のときは最も強いマイナスの相関がある。
一見は百聞にしかず。ある相関係数をもったデータの組を散布図で見てみよう。
量質ともに膨大な統計学リソースを提供している青木先生によるRのページhttp://aoki2.si.gunma-u.ac.jp/R/から、「特定の相関係数を持つ二変量データを生成する関数」を借用する。
gendat2 <- function(nc, r)
{
# 仮のデータ行列を作る。この時点では変数間の相関は近似的に0である。
z <- matrix(rnorm(2*nc), ncol=2)
# 主成分分析を行い,主成分得点を求める。この時点で変数間の相関は完全に0である。
res <- eigen(r2 <- cor(z))
coeff <- solve(r2) %*% (sqrt(matrix(res$values, 2, 2, byrow=TRUE))*res$vectors)
z <- t((t(z)-apply(z, 2, mean))/sqrt(apply(z, 2, var)*(nc-1)/nc)) %*% coeff
# コレスキー分解の結果をもとに,指定された相関係数行列 を持つように主成分得点を変換する。
z %*% chol(matrix(c(1, r, r, 1), ncol=2))
}
使い方は、
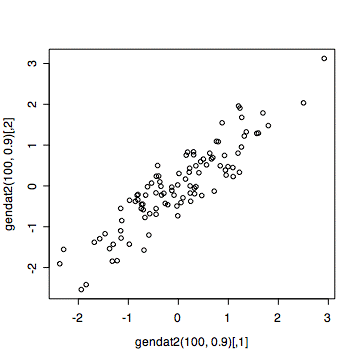
相関係数0.9のデータを100組つくって、その散布図を描く。
相関係数0.9のデータを100組つくって、その散布図を描く。
plot(gendat2(100,0.9))
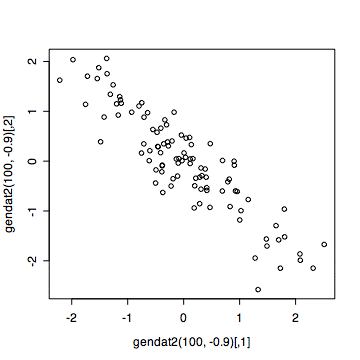
相関係数ー0.9のデータを100組つくって、その散布図を描く。
plot(gendat2(100,-0.9))
相関係数0.2のデータを100組つくって、その散布図を描く。
plot(gendat2(100,0.2))
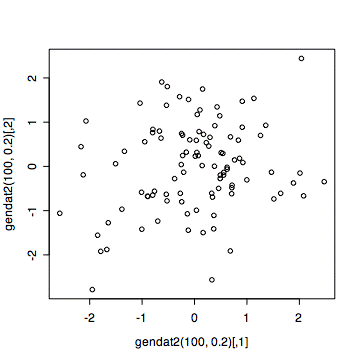
相関係数の絶対値が1に近づくほど、データはある直線の上に近づくように見える。
