普通は平均値から計算するものだが、いろいろ都合があるのである。さきに中央値からやらせてもらう。
中央値
##成績データを使って計算してみよう。
##中央値とは、データを小さな順に並べて、データの総数の半分のところに来るものである。成績データは31個のデータからなるから、小さい順に並べて16番目に来たものが中央値になる。
##中央値とは、データを小さな順に並べて、データの総数の半分のところに来るものである。成績データは31個のデータからなるから、小さい順に並べて16番目に来たものが中央値になる。
##Rには中央値を計算してくれる関数があるので、それを使えば一発である。
median(seiseki) [1] 73
##実は、中央値とデータそれぞれと差の絶対値の合計が最小になるのが中央値である。
これはつまり、中央値とデータとの距離の合計が最小になる、ということである。
逆に言えば、データのそれぞれから離れた(距離の大きい)値を、我々はそのデータ全体を代表する値として選ばないだろう。
データからの離れ具合の最も小さいもの=データそれぞれとの距離の合計が最も小さいものを、そのデータ全体を代表する値として選ぶだろう。
中央値とはまさしく、そのような値なのである。
これはつまり、中央値とデータとの距離の合計が最小になる、ということである。
逆に言えば、データのそれぞれから離れた(距離の大きい)値を、我々はそのデータ全体を代表する値として選ばないだろう。
データからの離れ具合の最も小さいもの=データそれぞれとの距離の合計が最も小さいものを、そのデータ全体を代表する値として選ぶだろう。
中央値とはまさしく、そのような値なのである。
##ためしに1~100の数字を候補として、他の値との差の絶対値の合計を計算してみよう。
kouho<-0
for(i in 1:100){kouho<-c(kouho,sum(abs(seiseki-i)))}
kouho
[1] 0 2198 2167 2136 2105 2074 2043 2012 1981 1950 1919 1888 1857 1826 1795
[16] 1764 1733 1702 1671 1640 1609 1578 1547 1516 1485 1454 1423 1392 1361 1332
[31] 1303 1274 1245 1216 1189 1162 1135 1108 1081 1054 1027 1000 973 946 921
[46] 896 871 846 821 796 771 750 729 710 691 674 657 640 623 606
[61] 589 572 557 544 531 518 505 494 483 472 461 456 451 448 449
[76] 450 455 460 465 470 475 482 489 500 511 522 537 554 575 596
[91] 619 642 665 688 713 738 763 788 813 842 871
##最初にダミーの0が混じっているので取り除く
kouho<-kouho[-1] kouho [1] 2198 2167 2136 2105 2074 2043 2012 1981 1950 1919 1888 1857 1826 1795 1764 [16] 1733 1702 1671 1640 1609 1578 1547 1516 1485 1454 1423 1392 1361 1332 1303 [31] 1274 1245 1216 1189 1162 1135 1108 1081 1054 1027 1000 973 946 921 896 [46] 871 846 821 796 771 750 729 710 691 674 657 640 623 606 589 [61] 572 557 544 531 518 505 494 483 472 461 456 451 448 449 450 [76] 455 460 465 470 475 482 489 500 511 522 537 554 575 596 619 [91] 642 665 688 713 738 763 788 813 842 871
##グラフを書いてみる。
plot(kouho)
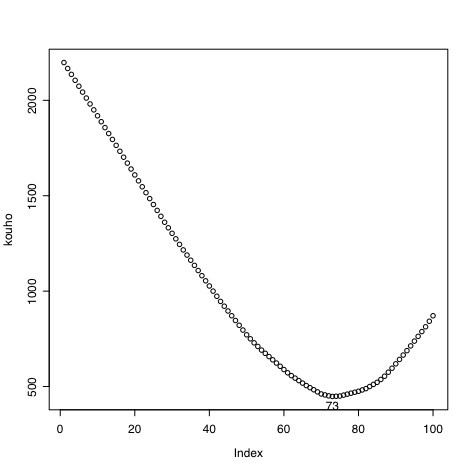
##この中で最小なのは
min(kouho) [1] 448
##では最小の値をとるiは
which(kouho==448) [1] 73
##73であった。これはmedian(seiseki)の値と一致する。
平均値
##成績データを使って計算してみよう。
#Rには平均値を求める関数が用意されているので
、それを使えば一発である。
mean(seiseki) [1] 71.90323
#それぞれの値を合計を求めて
、それを値の個数で割ると平均が求められる。
sum(seiseki) #合計を求める [1] 2229 length(seiseki) #値の個数を求める [1] 31 sum(seiseki)/length(seiseki) #合計を値の個数で割る [1] 71.90323
##当然だがmean(seiseki)で求めた値と一致する。
##平均値は、それぞれの値と平均値の差を合計すると、ゼロになる値である。
##これも実際にやってみよう。
##これも実際にやってみよう。
heikin_ten<-mean(seiseki) #平均値をheikin_tenの中に入れる。 heikin_karano_sa<-seiseki-heikin_ten #seisekiのそれぞれの値から平均値を引いたものをheikin_karano_saに入れる。
heikin_karano_sa #平均値からの差を表示。 [1] -21.9032258 10.0967742 -1.9032258 -17.9032258 3.0967742 0.0967742 [7] -1.9032258 -38.9032258 8.0967742 -19.9032258 26.0967742 1.0967742 [13] -9.9032258 1.0967742 -28.9032258 14.0967742 21.0967742 13.0967742 [19] -10.9032258 17.0967742 26.0967742 -43.9032258 15.0967742 28.0967742 [25] -21.9032258 15.0967742 -5.9032258 10.0967742 13.0967742 -1.9032258 [31] 3.0967742
sum(heikin_karano_sa) #「平均値からの差」を合計すると [1] -8.526513e-14 #計算誤差のためゼロにならないが非常に小さな数である。 round(sum(heikin_karano_sa)) #丸めるとゼロになる。 [1] 0
##それぞれの値と平均値の差を合計すると、ゼロになるということは、
##それぞれの値と平均値の差の二乗和を最小にできるということでもある。
##試しにやってみよう(ただし整数値刻みでやるので、上の中央値の例ほど、きれいな結果は出ない)
##それぞれの値と平均値の差の二乗和を最小にできるということでもある。
##試しにやってみよう(ただし整数値刻みでやるので、上の中央値の例ほど、きれいな結果は出ない)
kouho<-0
for(i in 1:100){kouho<-c(kouho,sum((seiseki-i)^2))}
kouho<-kouho[-1] #最初にダミーの0が混じっているので取り除く
kouho
[1] 166238 161873 157570 153329 149150 145033 140978 136985 133054 129185 125378 121633 117950 114329
[15] 110770 107273 103838 100465 97154 93905 90718 87593 84530 81529 78590 75713 72898 70145
[29] 67454 64825 62258 59753 57310 54929 52610 50353 48158 46025 43954 41945 39998 38113
[43] 36290 34529 32830 31193 29618 28105 26654 25265 23938 22673 21470 20329 19250 18233
[57] 17278 16385 15554 14785 14078 13433 12850 12329 11870 11473 11138 10865 10654 10505
[71] 10418 10393 10430 10529 10690 10913 11198 11545 11954 12425 12958 13553 14210 14929
[85] 15710 16553 17458 18425 19454 20545 21698 22913 24190 25529 26930 28393 29918 31505
[99] 33154 34865
最小値をとる整数値は、
which(kouho==min(kouho)) [1] 72
平均値の
mean(seiseki) [1] 71.90323
に一番近い整数値が得られた。
さらに強力(強引)かつ精密にやるには、関数の最大・最小化に使える関数optim()を使う方法がある。
まず最小化したい関数を定義する。それぞれの値との差の二乗和を最小にできるのが平均値であるから、
先の成績データseisekiを関数内にぶちこんで、二乗和の計算にはベクトルの内積を計算することで、これに代える。
関数は以下のようになる。
Fmean<-function(x){
seiseki<-c(50,82,70,54,75,72,70,33,80,52,98,73,62,73,43,86,93,85,61,89,98,28,87,100,50,87,66,82,85,70,75)
return( (seiseki-x)%*%(seiseki-x) )}
これを関数optim()で最小化する。適当な初期値(ここでは、ものぐさにも初期値=1とした)を与えるだけで、計算してくれる。
optim(1,Fmean) $par [1] 71.9 (中略) Warning message: one-diml optimization by Nelder-Mead is unreliable: use >optimize in: optim(1, Fmean)
警告メッセージが出た。optim()の最小化法はいくつかから選べるが、デフォルトのNelder-Mead法は今回のような場合にはunreliable(信頼できない)と言う。
ならば違う方法("SANN" 法=確率的手法であるいわゆるシミュレーテッド・アニーリング法。)を使うことにしよう。method="SANN"としてやるだけで良い。
ならば違う方法("SANN" 法=確率的手法であるいわゆるシミュレーテッド・アニーリング法。)を使うことにしよう。method="SANN"としてやるだけで良い。
optim(1,Fmean,method="SANN")
$par [1] 71.90324
(以下略)
それぞれの値との差の二乗和を最小する方法で、
平均値のmean(seiseki) [1] 71.90323
に十分に近い精度の答えが出た。
これまでのような数値例では納得できない人は、数式を変形して証明することも可能である。
まず、それぞれの値と平均値の差の二乗和を数式で表そう。
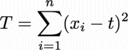
は、それぞれの値xiと平均値(になるはずの数)tの差を表す。
は、それぞれの値と平均値の差の二乗
はそれぞれの値と平均値の差の二乗和である。
このT(それぞれの値と平均値の差の二乗和)を最小化するtを求めてみる(平均値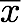 と同じになるはずである)。
と同じになるはずである)。
まず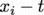 から平均値を足して引いても式の値は変わらないから
から平均値を足して引いても式の値は変わらないから
である。
これを2乗すると
これを2乗すると
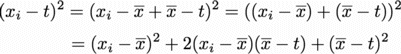
したがって
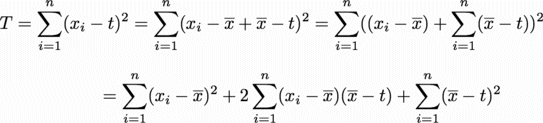
である。
さて元々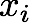 の平均値は、(i=1~n)をすべて足し合わせてnで割ったもの
の平均値は、(i=1~n)をすべて足し合わせてnで割ったもの
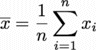
であるから、平均をn個足し合わせた
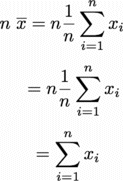
は、ご覧の通り(i=1~n)をすべて足し合わせものと等しい。
したがって
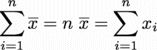 から
から
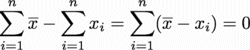 であり、
であり、
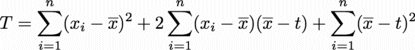
の第2項は
で0である。
さて我々が最小化したいTは、結局、
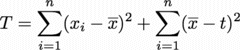
というところまで簡単になった。あと一息である。
第1項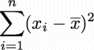 について考えると、
について考えると、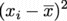 はゼロかプラスのいずれかであろうから、それらを足し合わせたはプラスに違いない。
はゼロかプラスのいずれかであろうから、それらを足し合わせたはプラスに違いない。
第1項
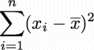 について考えると、はプラスに違いない。
について考えると、はプラスに違いない。
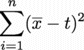 についても同様で、
についても同様で、
それ故に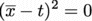 である。つまり、
である。つまり、
したがって、それぞれの値と平均値の差の二乗和Tを最小化できるtとは、xiの平均値と等しくなければならないことが証明された。えっへん。
(じつはこれは、回帰直線を求める最小自乗法の前振り/長すぎる助走なのである。同様の数式の展開に、最小自乗法で回帰直線を求めるときに我々は再会するだろう)。
最頻値
##最頻値は、頻度分布で最も大きい頻度をもつ値。
##ヒストグラムをつくるhist()は、グラフを表示せず(plot=Fと指定してやればいい)計算だけをやってくれるので、結果をresultという変数に一旦格納する。
##ヒストグラムをつくるhist()は、グラフを表示せず(plot=Fと指定してやればいい)計算だけをやってくれるので、結果をresultという変数に一旦格納する。
result<-hist(seiseki,plot=F)
##さて、resultの中身はと言うと、
result $breaks [1] 20 30 40 50 60 70 80 90 100 $counts [1] 1 1 3 2 6 6 8 4 $intensities [1] 0.003225806 0.003225806 0.009677419 0.006451613 0.019354839 0.019354839 0.025806452 0.012903226 $density [1] 0.003225806 0.003225806 0.009677419 0.006451613 0.019354839 0.019354839 0.025806452 0.012903226 $mids [1] 25 35 45 55 65 75 85 95 $xname [1] "seiseki" $equidist [1] TRUE attr(,"class") [1] "histogram"
##いろんな種類の値をパッケージしてあるようだ。こういうのをデータフレームと呼ぶ。
##データフレーム内のそれぞれの値を呼び出したり書き換えたりするには、正式には
##データフレーム内のそれぞれの値を呼び出したり書き換えたりするには、正式には
データフレーム名$列名
などとすればいい。
##とりあえず必要なのは、それぞれの度数であるcountsと区間を表すbreaksである。
##とりあえず必要なのは、それぞれの度数であるcountsと区間を表すbreaksである。
##最も多い度数はmax(result$counts)で求めることが出来る。これは 8 である。
##次に8の度数をもつのは何番目かどうかを知るにはwhichをつかう。
##次に8の度数をもつのは何番目かどうかを知るにはwhichをつかう。
which(result$counts==8) [1]7
7番目である。あとは7番目の区間がどれか求めれば良い。
result$breaks[7] [1] 80
これを1行で書けばこうなる
result$breaks[which(result$counts==max(result$counts))] [1] 80
これが最頻値である。
実際にヒストグラムをかいて確かめるとよい。図は省略する。
hist(seiseki)
