このサンプルPDFは、秀丸からDocuCom PDF Driverに出力しています。12/20の段階で、印刷機能をプログラムしました。位置は、自動で中央配置、縦長・横長の自動判定、文字も用紙に対して最大になるよう自動調整で印刷します。文字情報から印刷データを作成するので、画像保存とは比較にならないきれいさで印刷します。
var x,y:integer;
begin
Image1.Canvas.Font.Name:='MS ゴシック';
Image1.Canvas.Font.Size:=60;
y:=Image1.Canvas.TextHeight('問');
x:=Image1.Canvas.TextWidth('問');
Edit2.Text:=IntToStr(x)+':'+IntToStr(y)
end;
var moji_haba:integer;を先頭の方に記述して、それにさっきの実験でx=yだったので、どっちか1つ確認すればOK。
procedure TForm1.FormCreate(Sender: TObject);
begin
Image1.Canvas.Font.Name:='MS ゴシック';
Image1.Canvas.Font.Size:=60;
moji_haba:=Image1.Canvas.TextWidth('問');
end;
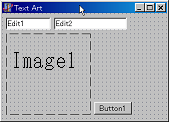
では、今度はButton1に文字の占める面積に対する黒の比率を求めてみましょう。
procedure TForm1.Button1Click(Sender: TObject);
var x,y,n:integer;
begin
Image1.Canvas.Font.Color:=clBlack;
Image1.Canvas.TextOut(0,0,Edit1.Text);
n:=0;
for y:=0 to moji_haba-1 do for x:=0 to moji_haba-1 do
if Image1.Canvas.Pixels[x,y]=clBlack then n:=n+1;
Edit2.Text:=IntToStr(round(n/moji_haba/moji_haba*100))+'%';
end;
麒麟の字でもそれぞれ42%、44%.....半分未満です。(ここまで2009/11/24)
1つ1つ濃淡を調べて並べ替えるのは面倒なので、まずButton1の内容を汎用関数化します。
private
{ Private 宣言 }
function noutan(kan:string):integer;
functionの1行を宣言部分に書き加えて、中身はほとんどそのまま。
function TForm1.noutan(kan:string):integer;
var x,y,n:integer;
begin
Image1.Picture.Bitmap.PixelFormat:=pf1bit;
Image1.Canvas.Font.Color:=clBlack;
Image1.Canvas.TextOut(0,0,kan);
n:=0;
for y:=0 to moji_haba-1 do for x:=0 to moji_haba-1 do
if Image1.Canvas.Pixels[x,y]=clBlack then n:=n+1;
noutan:=round(n/moji_haba/moji_haba*100);
end;
で、Button1は以下のように書けばOKです。
procedure TForm1.Button1Click(Sender: TObject);
begin
Edit2.Text:=IntToStr(noutan(Edit1.Text))+'%';
end;
for x:=0 to length(data) div 2-1 do kanji[x]:=copy(data,x*2+1,2);
Memo1を追加しましょう。その上でButton1の内容は、
procedure TForm1.Button1Click(Sender: TObject);
var i,j,n,l:integer; k:string;
begin
l:=length(data) div 2-1;
for i:=0 to l do
begin
k:=kanji[i]; BW[i]:=noutan(k);
Memo1.Lines.Add(IntToStr(i+1)+' '+k+','+IntToStr(BW[i])+'%');
end;
end;
for i:=0 to l-1 do {この行から並べ替え}
begin
for j:=i to l do
if BW[i]>BW[j] then
begin
k:=kanji[i]; kanji[i]:=kanji[j]; kanji[j]:=k;
n:=BW[i]; BW[i]:=BW[j]; BW[j]:=n;
end;
end;
for i:=0 to l do {再度表示}
begin
k:=kanji[i]; BW[i]:=noutan(k);
Memo1.Lines.Add(IntToStr(i+1)+' '+k+','+IntToStr(BW[i])+'%');
end;
procedure TForm1.Button2Click(Sender: TObject);
var x,y:integer; n,g:longint; dam:string;
begin Memo1.Lines.Clear;
Image1.Picture.LoadFromFile('test.bmp');
for y:=0 to Image1.Height-1 do
begin
dam:='';
for x:=0 to Image1.Width-1 do
begin
n:=Image1.Canvas.Pixels[x,y];
g:=n div $10000; n:=N mod $10000;
g:=((g+(n div $100)+(n mod $100)) div 3) div 8;
dam:=dam+kanji[Cmax-g];
end;
Memo1.Lines.Add(dam);
end;
Memo1.Lines.SaveToFile('test.csv');
end;
procedure TForm1.Button3Click(Sender: TObject);
var i,l,n:integer; dam,K_data:string;
const F_name='濃淡.txt';
begin
if FileExists(F_name)=false then
begin
Memo1.Lines.Clear;
for i:=0 to 60 do Memo1.Lines.Add(IntToStr(i)+',');
Memo1.Lines.SaveToFile(F_name);
end;
//-------------------------------
Edit2.SelectAll; Edit2.PasteFromClipboard;
Memo1.Lines.LoadFromFile(F_name);
K_data:=Edit2.Text;
l:=length(K_data) div 2;
for i:=0 to l do
begin
dam:=copy(K_data,i*2+1,2);
n:=noutan(dam);
Memo1.Lines[n]:=Memo1.Lines[n]+dam;
end;
Memo1.Lines.SaveToFile(F_name);
end;
function bunri(dat,c,f:string):string;
var p,l,cl:integer;
begin
l:=length(dat); p:=pos(c,dat); cl:=length(c)-1;
if f='-' then bunri:=copy(dat,1,p-1);
if f='+' then bunri:=copy(dat,p+1+cl,l-p-cl);
end;
この関数は、特定の最初にあるc文字の前か後ろを取り出すものです。さらに、
var kanji:array[0..100,0..8] of string; BW:array[0..100] of integer;
moji_haba, Cmax:integer;
グローバルの定数はなくして、変数に変えて、
function PixToKan(P_noutan,P_katayori:integer):string;
var l:integer; dam: string;
begin
l:=length(kanji[P_noutan,P_katayori]);
if l=2 then dam:=kanji[P_noutan,P_katayori]
else
begin
l:=Random(l div 2)*2+1;
dam:=copy(kanji[P_noutan,P_katayori],l,2);
end;
PixToKan:=dam;
end;
procedure TForm1.FormCreate(Sender: TObject);
var x:integer;
begin
Memo1.Lines.Clear;
Memo1.Lines.LoadFromFile('濃淡0.txt');
Cmax:=Memo1.Lines.Count-1;
for x:=0 to Cmax do kanji[x,0]:=bunri(Memo1.Lines[x],',','+');
Memo1.Lines.Clear;
Randomize;
end;
初期設定もこんなに変ります。濃淡0.txtのファイルは、サンプルでつけてあります。
procedure TForm1.Button2Click(Sender: TObject);
var x,y:integer; n,g:longint; dam:string;
begin
Memo1.Lines.Clear;
Image1.Picture.LoadFromFile('test.bmp');
for y:=0 to Image1.Height-1 do
begin
dam:='';
for x:=0 to Image1.Width-1 do
begin
n:=Image1.Canvas.Pixels[x,y];
g:=n div $10000; n:=N mod $10000;
g:=round(((g+(n div $100)+(n mod $100)) div 3)/(256/cmax));
dam:=dam+PixToKan(Cmax-g,0);
end;
Memo1.Lines.Add(dam);
end;
Memo1.Lines.SaveToFile('test.csv');
end;
function TForm1.noutan4(kan:string):integer;
function Q_noutan(x1,y1,hen:integer):integer;
var x,y,n:integer;
begin
n:=0;
for y:=y1 to y1+hen-1 do for x:=x1 to x1+hen-1 do
if Image1.Canvas.Pixels[x,y]=clBlack then n:=n+1;
Q_noutan:=round(n/hen/hen*100);
end;
var Han_Haba:integer;
begin
Image1.Picture.Bitmap.PixelFormat:=pf1bit;
Image1.Canvas.Font.Color:=clBlack;
Image1.Canvas.TextOut(0,0,kan);
Han_Haba:=Moji_haba div 2;
noutan4:=Q_noutan(0,0,Han_Haba)*1000000+Q_noutan(Han_Haba,0,Han_Haba)*10000
+Q_noutan(0,Han_Haba,Han_Haba)*100+ Q_noutan(Han_Haba,Han_Haba,Han_Haba);
end;
function Katayori(n1,n2,n3,n4,nt:integer):integer;
var nt_s,K_type,sa12,sa34:integer;
begin
nt_s:=round(nt*3*(1-nt/7/cmax)) div 2; { 偏り指数 }
K_type:=0;
sa12:=((n1+n3)-(n2+n4))*3; if abs(sa12)<nt_s then sa12:=0;
if sa12>0 then K_type:=1;
if sa12<0 then K_type:=2;
sa34:=((n1+n2)-(n3+n4))*3; if abs(sa34)<nt_s then sa34:=0;
if abs(sa12)<abs(sa34) then
begin
if sa34>0 then K_type:=3;
if sa34<0 then K_type:=4;
sa12:=sa34;
end;
sa34:=(n1*3-(n2+n3+n4))*2; if abs(sa34)<nt_s then sa34:=0;
if abs(sa12)<abs(sa34) then
begin
if sa34>0 then K_type:=5;
if sa34<0 then K_type:=8;
sa12:=sa34;
end;
sa34:=(n2*3-(n1+n3+n4))*2; if abs(sa34)<nt_s then sa34:=0;
if abs(sa12)<abs(sa34) then
begin
if sa34>0 then K_type:=6;
if sa34<0 then K_type:=7;
sa12:=sa34;
end;
sa34:=(n3*3-(n1+n2+n4))*2; if abs(sa34)<nt_s then sa34:=0;
if abs(sa12)<abs(sa34) then
begin
if sa34>0 then K_type:=7;
if sa34<0 then K_type:=6;
sa12:=sa34;
end;
sa34:=(n4*3-(n1+n2+n3))*2; if abs(sa34)<nt_s then sa34:=0;
if abs(sa12)<abs(sa34) then
begin
if sa34>0 then K_type:=8;
if sa34<0 then K_type:=5;
sa12:=sa34; {<=コンパイルしたら、この行は、いらないって...}
end;
Katayori:=K_type;
end;
Memo1.Lines.LoadFromFile('MSG.csv');
Cmax:=Memo1.Lines.Count-1;
for x:=0 to Cmax do
begin
dam:=bunri(Memo1.Lines[x],',','+');
for y:=0 to 7 do
begin
kanji[x,y]:=bunri(dam,',','-');
dam:=bunri(dam,',','+');
end;
kanji[x,8]:=dam;
end;
procedure TForm1.Button5Click(Sender: TObject);
var x,y,xx,yy,ImgX,ImgY, Gr1,Gr2,Gr3,Gr4,GrT:integer; g:longint; dam:string;
begin Memo1.Lines.Clear;
Image1.Picture.LoadFromFile('test2.bmp');
ImgX:=Image1.Width div 2;
ImgY:=Image1.Height div 2;
for yy:=0 to ImgY-1 do
begin
dam:='';
for xx:=0 to ImgX-1 do
begin
x:=xx*2; y:=yy*2;
Gr1:=Gray(Image1.Canvas.Pixels[x,y]);
Gr2:=Gray(Image1.Canvas.Pixels[x+1,y]);
Gr3:=Gray(Image1.Canvas.Pixels[x,y+1]);
Gr4:=Gray(Image1.Canvas.Pixels[x+1,y+1]);
GrT:=Katayori(Gr1,Gr2,Gr3,Gr4,(Gr1+Gr2+Gr3+Gr4) div 4);
g:=round((Gr1+Gr2+Gr3+Gr4)*Cmax/256/4);
dam:=dam+PixToKan(Cmax-g,GrT);
end;
Memo1.Lines.Add(dam);
end;
Memo1.Lines.SaveToFile('Test2.txt');
end;
function TForm1.Kukaku(x,y,d:integer):string;
function _kukaku(xl1,xl2,yl1,yl2:integer):integer;
var ix1,iy1,n1:integer; Ttl:Longint;
begin
n1:=0; Ttl:=0;
for ix1:=xl1 to xl2 do for iy1:=yl1 to yl2 do
begin n1:=n1+1; Ttl:=Ttl+Gray(Image1.Canvas.Pixels[ix1,iy1]); end;
_kukaku:=Ttl div n1;
end;
var md,x2,x3,x4,y2,y3,y4, g,Gr1,Gr2,Gr3,Gr4,GrT:integer;
begin {x->x2, x3,x4}
md:=d div 2; {y->y2 1 2 }
x2:=x+md-1; x3:=x+md; x4:=x+d-1; {y3-.y4 3 4 }
y2:=y+md-1; y3:=y+md; y4:=y+d-1;
Gr1:=_kukaku(x,x2,y,y2);
Gr2:=_kukaku(x3,x4,y,y2);
Gr3:=_kukaku(x,x2,y3,y4);
Gr4:=_kukaku(x3,x4,y3,y4);
GrT:=Katayori(256-Gr1,256-Gr2,256-Gr3,256-Gr4,256-((Gr1+Gr2+Gr3+Gr4) div 4));
g:=round((Gr1+Gr2+Gr3+Gr4)*Cmax/256/4);
Kukaku:=PixToKan(Cmax-g,GrT);
end;
ためしにButtonに組み込んでみましょう。
procedure TForm1.Button9Click(Sender: TObject);
const k=4;
var x,y,xx,yy,ImgX,ImgY:integer; dam:string;
begin
Memo1.Lines.Clear;
Image1.Picture.LoadFromFile(Edit2.Text);
ImgX:=Image1.Width div k;
ImgY:=Image1.Height div k;
for yy:=0 to ImgY-1 do
begin
dam:='';
for xx:=0 to ImgX-1 do
begin
x:=xx*k; y:=yy*k;
dam:=dam+Kukaku(x,y,k);
end;
Memo1.Lines.Add(dam);
end;
shomei(ImgX,ImgY);
Memo1.Lines.SaveToFile(F_Ext(Edit2.Text,'txt'));
end;
function fitChrSize(haba:integer):integer; const s='問';
begin
TCan.Font.Height:=1;
with Tcan do
begin
if TextHeight(s)<haba then
repeat
font.Height:=font.Height+1;
until haba<TextHeight(s);
fitChrSize:=font.Height-1;
end;
end;
begin
if Prn=False then
begin
TCan.Brush.Color:=clWhite; TCan.Pen.Color:=clWhite;
TCan.Rectangle(0,0,Pwidth-1,Pheight-1);
end;
TCan.Font.Name:=Memo1.Font.Name;
moji_X:=length(Memo1.Lines[0]) div 2;
moji_Y:=Memo1.Lines.Count;
// 余白計算
if Pwidth<Pheight
then begin yohaku_X:=round(Pwidth*yohaku_hi); yohaku_Y:=yohaku_X; end
else begin yohaku_Y:=round(Pheight*yohaku_hi); yohaku_X:=yohaku_Y; end;
inji_X:=Pwidth-yohaku_X*2;
inji_Y:=Pheight-yohaku_Y*2;
// 文字幅計算
if ((moji_X/moji_Y)<(inji_X/inji_Y))
then Pmoji_haba:=inji_Y div moji_Y
else Pmoji_haba:=inji_X div moji_X;
// 余白 再調整
yohaku_X:=(Pwidth -moji_X*Pmoji_haba) div 2;
yohaku_Y:=(Pheight-moji_Y*Pmoji_haba) div 2;
TCan.Font.Height:=fitChrSize(Pmoji_haba);
TCan.Font.Color:=0;
// canvasに書き込み
for iy:=0 to moji_Y-1 do
begin
for ix:=0 to moji_X-1 do
begin
xx:=ix*Pmoji_haba+yohaku_X;
yy:=iy*Pmoji_haba+yohaku_Y;
TCan.TextOut(xx,yy, copy(Memo1.Lines[iy],ix*2+1,2));
end;
end;
end;
var num:integer;
begin
Image3.Stretch:=False; Im3_By:=0;
if Memo1.Lines.Count>0 then
with Image3 do
begin
Width:=640*2; Height:=480*2;
if Memo1.Lines.Count>length(Memo1.Lines[0]) div 2 then
begin num:=Width; Width:=Height; Height:=num; end;
kijutu(Canvas, Width, Height, False);
end;
end;
begin
if MessageDlg('印刷しますか?', mtConfirmation, mbOKCancel, 0) = id_OK then
begin
if Memo1.Lines.Count<length(Memo1.Lines[0]) div 2
then Printer.Orientation := poLandscape
else Printer.Orientation := poPortrait;
try
with Printer do
begin
Title:=Edit2.Text;
BeginDoc;
kijutu(canvas,PageWidth,PageHeight, True);
EndDoc;
end;
finally
end;
end;
end;
2つ目のif文が、横長、縦長の判断です。とりあえず、このへんまでが主なルーチンの記述で、後は、
ファイルの読み込みをどうするか。
書き出しのときの、ファイル名をどうするか。
Text Fileを保存するのかしないのか。Memo objectに書き出しているので1行があまり大きいとエラーを起こす。


 ここ
ここ







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}